Motiviations for a CDC
As we scale systems to handle more complicated business-logic and business needs, we often need to extend the data-storage capabilities of existing systems to pave way for things like data-warehouses, caches, read/write copies, etc. With all of these duped locations for data-storage / retrieval, there needs to be a method to actually sync all of these storage-locations together, when change does occur.
Usually, when you have multiple copies of the same data, you will appoint one as the source-of-truth (system of records data) and the rest as derived-data. To keep the system of records data and the derived-data in sync, we often use cdcs that can navigate/handle this complexity.
CDC
A CDC is the process of observing all data changes written to a database and extracting them in a form in which they can be replicated to derived data systems.
In general, a CDC process has three main stages:
- Change Detection
- Change Capture
- Change Propagation
Change Detection Methods
The three main methods of change-detection are:
- Polling
- Database write triggers
- Monitoring the database transaction-log for changes
Of the three, most modern CDC systems monitor the db transaction log as it resource-cheap and relatively fast.
System Requirements for CDCs
- Message ordering guarantee: The order of changes MUST BE preserved so that they are propagated to the target systems as is.
- Sub: Should support asynchronous, pub/sub style change propagation to consumers.
- Reliable and resilient delivery: At-leat-once delivery of changes. Cannot tolerate a message loss.
- Message transformation support: Should support light-weight message transformations as the event payload need to match with the target system’s input format.
With these requirements, event-driven architecture seems like the best choice to carry out these operations. Take a look at this diagram to see what this CDC architecture will look like:
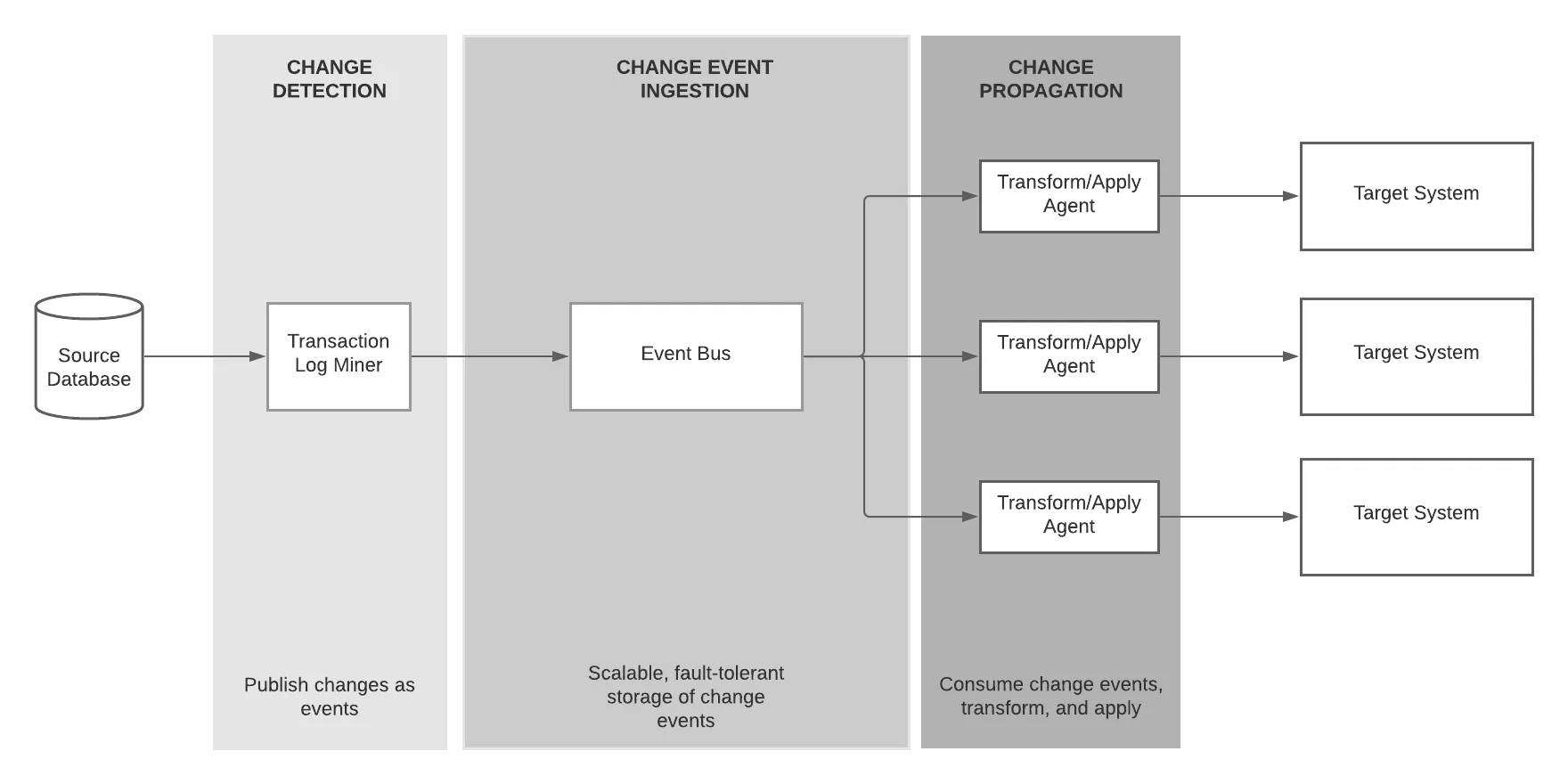
Use-Cases for CDCs
- Cache Invalidation
- Search Index Building
- Database Migrations (publishing to two DBs rather than just one)
- Offline Analytics processing (moving data to warehouses/lake houses)
- Data Synchronization in Microservices
Main Vendors in the Market
- Debezium (CDC) is an open-source CDC platform built on top of Apache Kafka
- Maxwell
Suggested Readings
Linked Map of Contexts