Key Value Databases (Redis, Memcached)
Brief Summary of Database/Technology Key-value Databases are structured similarly to JavaScript objects or Python dictionaries, where each key is unique and maps to a value. All data is held in the machine’s memory rather than on disk, enabling sub-millisecond response times. This in-memory architecture makes them exceptionally fast for read and write operations since there’s no need for disk I/O round trips.

Real-World Example Instagram Feed Caching: Instagram uses Redis to cache user feeds and reduce load on their primary databases. When a user opens Instagram, their feed could require aggregating posts from hundreds of accounts they follow, applying ranking algorithms, and filtering content—an operation that would be too slow if performed on-demand from disk-based databases. Instead, Instagram pre-computes and caches feeds in Redis. When a user with millions of followers posts a photo, that content is immediately pushed to Redis caches of their followers’ feeds. This allows Instagram to serve feeds in under 100ms even during peak traffic, handling billions of feed requests daily. Without Redis, their PostgreSQL databases would be overwhelmed with read queries, and users would experience multi-second load times.
Redis - Instagram Feed Cache
| Key | Value (JSON Array) | TTL |
|---|---|---|
| feed:user:123456 | [{post_id: abc123, user: 789, likes: 1250}, {post_id: def456, user: 321, likes: 890}] | 300s |
| feed:user:789012 | [{post_id: xyz999, user: 111, likes: 3400}, {post_id: lmn888, user: 222, likes: 567}] | 300s |
Example Cases for the Database
- Caching layer to reduce database load and improve application performance
- Message queues for asynchronous task processing
- Sub systems for real-time messaging and notifications
- Session storage for web applications
When not to Use the Database Avoid key-value databases when you need complex queries, data relationships, or persistent storage guarantees. They’re not suitable for data that requires ACID transactions or when memory constraints are a concern.
| Pros | Cons |
|---|---|
| Extremely fast (sub-millisecond) | Limited to available memory |
| Simple data structure | No complex querying capabilities |
| High throughput | Volatile without persistence config |
| Easy to implement | No built-in relationships |
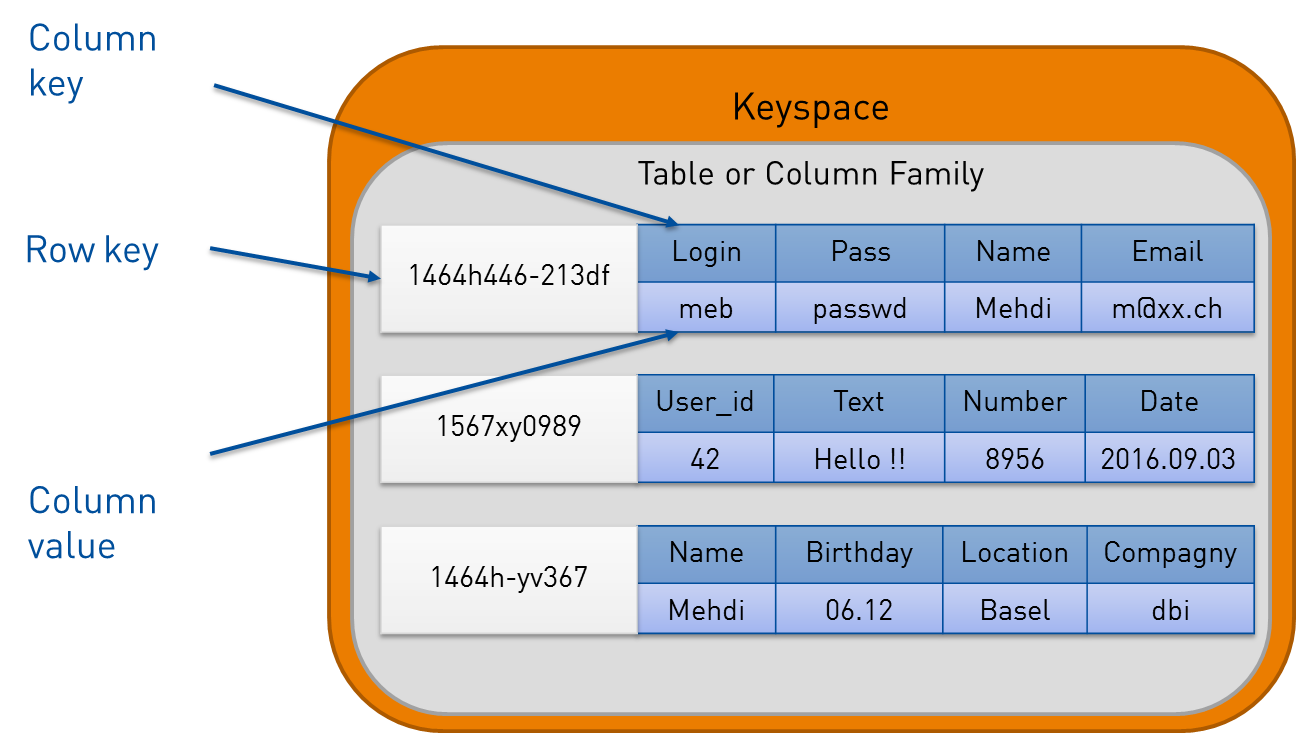
Wide Column Databases (Cassandra, HBase)
Brief Summary of Database/Technology Wide column databases extend the key-value model by adding a second dimension. Each key in the key space can hold one or more column families within rows, allowing for flexible data organization. These databases sacrifice the ability to perform joins in exchange for exceptional horizontal scalability and replication capabilities, making them ideal for distributed systems handling massive datasets.
Real-World Example Netflix Viewing History: Netflix uses Apache Cassandra to store viewing history and preferences for over 200 million subscribers worldwide. Every time you pause, rewind, or finish watching a show, that event is recorded. Netflix needs to track not just what you watched, but timestamps, device information, watch duration, and playback positions across every episode. This generates billions of write operations daily. With Cassandra’s wide column structure, Netflix can use a user ID as the partition key and store time-series data (viewing events) as columns within that partition. When you open Netflix, the app queries your viewing history from the geographically nearest Cassandra cluster for fast loading of “Continue Watching.” Cassandra’s masterless architecture means no single point of failure—if a data center goes down, Netflix can still serve your viewing data from replicas in other regions, ensuring 99.99% uptime for this critical feature.
Cassandra - Netflix Viewing History
| user_id | watch_timestamp | title_id | device_type | watch_duration | playback_position |
|---|---|---|---|---|---|
| 550e8400-e29b | 2025-10-15 20:30:00 | stranger-things-s4e1 | smart_tv | 3600 | 3245 |
| 550e8400-e29b | 2025-10-15 19:15:00 | breaking-bad-s1e1 | mobile | 2800 | 2800 |
| 550e8400-e29b | 2025-10-14 21:00:00 | the-crown-s5e3 | laptop | 3200 | 1500 |
Example Cases for the Database
- Time series data storage (Netflix watch history, user activity logs)
- IoT sensor data collection and analysis
- Event logging and analytics at massive scale
- Real-time analytics and monitoring systems
When not to Use the Database Avoid when your application requires complex joins between tables, strict ACID transactions across multiple rows, or when data is highly normalized and interconnected.
| Pros | Cons |
|---|---|
| Excellent horizontal scalability | No join operations |
| Handles massive datasets | Complex query limitations |
| High write throughput | Eventual consistency model |
| Built for replication | Denormalized data required |
Document Oriented Databases (MongoDB, CouchDB)
Brief Summary of Database/Technology Document-oriented databases store data as documents (typically JSON-like structures) without requiring a predefined schema. Documents are grouped into collections and can be indexed and organized hierarchically. This flexibility allows each document to have different fields, making these databases ideal for evolving data models. However, the lack of joins means data is often denormalized, leading to faster reads but more complex write operations when related data needs updating across multiple documents.
Real-World Example Uber Trip Data: Uber uses MongoDB to store trip information because each ride has vastly different attributes depending on the service type and region. A standard UberX ride might store: pickup/dropoff locations, driver ID, passenger ID, fare breakdown, and route taken. But an UberEats delivery includes restaurant details, food items, preparation time, and delivery instructions. An UberPool ride has multiple passengers with different pickup/dropoff points. In a relational database, this would require either many nullable columns or complex join tables. With MongoDB, each trip is a flexible document that can contain exactly the fields needed for that specific ride type. When displaying trip history in the Uber app, MongoDB can quickly retrieve all of a user’s trips without joins. The trade-off: when a driver updates their profile photo, Uber must update that information across potentially millions of trip documents where that driver appears, rather than just one row in a drivers table.
// MongoDB - Uber Trip Data
{
"_id": "trip_789xyz",
"tripType": "uberEats",
"timestamp": "2025-10-16T14:30:00Z",
"customer": {
"id": "user_123",
"name": "John Doe",
"phone": "+1234567890"
},
"driver": {
"id": "driver_456",
"name": "Jane Smith",
"photo": "https://...",
"rating": 4.8
},
"restaurant": {
"name": "Pizza Palace",
"location": {"lat": 37.7749, "lng": -122.4194}
},
"items": [
{"name": "Pepperoni Pizza", "quantity": 1, "price": 18.99},
{"name": "Garlic Bread", "quantity": 2, "price": 5.99}
],
"delivery": {
"pickup": {"lat": 37.7749, "lng": -122.4194, "time": "2025-10-16T14:45:00Z"},
"dropoff": {"lat": 37.7849, "lng": -122.4094, "time": "2025-10-16T15:10:00Z"},
"instructions": "Leave at door, ring bell"
},
"fare": {
"subtotal": 24.98,
"delivery_fee": 3.99,
"service_fee": 2.50,
"tip": 5.00,
"total": 36.47
},
"status": "completed"
}Example Cases for the Database
- Content management systems with varying content types
- Product catalogs with diverse attributes
- User profiles and settings
- Mobile applications requiring offline sync
- Flexible data models that change frequently
When not to Use the Database Avoid for highly interconnected data that changes frequently, such as social media interactions where comments, likes, and relationships need constant updates across multiple entities. Not ideal when data consistency across related documents is critical.
| Pros | Cons |
|---|---|
| Flexible schema | Complex writes with denormalized data |
| Fast read operations | No native join support |
| Easy to scale horizontally | Data duplication and inconsistency risk |
| Natural fit for JSON/object data | Difficult with highly relational data |
Relational Databases (PostgreSQL, MySQL, CockroachDB)
Brief Summary of Database/Technology Relational databases organize data into tables where each row has a primary key and can reference other tables through foreign keys. Data is structured in its smallest normal form to minimize redundancy. These databases are ACID compliant, ensuring that transactions maintain data consistency and integrity. The trade-off for this reliability is that they require a predefined schema and are traditionally more difficult to scale horizontally, though modern solutions like CockroachDB address scalability concerns.
Real-World Example Stripe Payment Processing: Stripe uses PostgreSQL to handle payment transactions because financial data demands absolute consistency and ACID guarantees. When a customer makes a purchase, Stripe must: (1) verify the customer’s payment method, (2) create a charge record, (3) deduct from the merchant’s fee balance, (4) create a transfer record, and (5) update account balances—all within a single atomic transaction. If any step fails (network issue, insufficient funds, etc.), the entire transaction must roll back to prevent data inconsistencies. Imagine if a charge succeeded but the merchant’s balance wasn’t credited—that’s money lost in the system. PostgreSQL’s foreign keys ensure referential integrity: you can’t delete a customer who has associated charges. Its strict schema prevents accidentally storing invalid data types. The cost is that scaling PostgreSQL requires sophisticated replication strategies, but for Stripe, correctness is non-negotiable—a 0.01% error rate on billions of dollars in transactions would be catastrophic. Every penny must be accounted for, which is why relational databases remain the gold standard for financial systems.
PostgreSQL - Stripe Transactions** Customers Table
| customer_id | name | created_at | |
|---|---|---|---|
| cust_123abc | alice@example.com | Alice Johnson | 2024-03-15 |
| cust_456def | bob@example.com | Bob Smith | 2024-05-22 |
Charges Table
| charge_id | customer_id | payment_method_id | amount | currency | status | created_at |
|---|---|---|---|---|---|---|
| ch_789xyz | cust_123abc | pm_111aaa | 99.99 | USD | succeeded | 2025-10-16 14:30 |
| ch_012uvw | cust_456def | pm_222bbb | 149.50 | USD | succeeded | 2025-10-16 15:45 |
Transfers Table
| transfer_id | charge_id | merchant_id | amount | fee | net_amount | status |
|---|---|---|---|---|---|---|
| tr_333ccc | ch_789xyz | merch_999 | 99.99 | 2.90 | 97.09 | paid |
| tr_444ddd | ch_012uvw | merch_888 | 149.50 | 4.34 | 145.16 | paid |
Example Cases for the Database
- Financial transactions and banking systems
- E-commerce order management and inventory
- Booking and reservation systems
- Enterprise resource planning (ERP) systems
- Any application requiring strict data consistency
When not to Use the Database Avoid when you need massive horizontal scaling without distributed database solutions, when your schema changes extremely frequently, or when eventual consistency is acceptable. Not ideal for unstructured data or when sub-millisecond latency is required.
| Pros | Cons |
|---|---|
| ACID compliance | Harder to scale horizontally |
| Strong data consistency | Requires predefined schema |
| Mature ecosystem and tooling | Can be slower for massive scale |
| Support for complex queries | Schema migrations can be complex |
| Data integrity guarantees | Traditional vertical scaling |
Graph Databases (Neo4j, Amazon Neptune)
Brief Summary of Database/Technology Graph databases model data as nodes (entities) with edges (relationships) connecting them. Instead of using join tables to establish relationships like in relational databases, graph databases store relationships as first-class citizens with edges pointing directly between nodes. This structure makes traversing complex relationships much more efficient and eliminates the need for expensive join operations when querying connected data.
Real-World Example LinkedIn Connection Recommendations: LinkedIn uses a graph database to power their “People You May Know” feature and calculate network distances between users. Each LinkedIn member is a node, and connections between members are edges. When LinkedIn suggests people you may know, it traverses your graph: it looks at your first-degree connections (friends), then their connections (friends-of-friends), identifies mutual connections, and ranks suggestions by the number of shared connections, companies, schools, and skills. In a relational database, this would require multiple self-joins on a users table—for instance, finding third-degree connections would need a query joining the connections table to itself three times, which becomes exponentially slower as the network grows. With LinkedIn’s 900+ million users, these queries would be impossibly slow. Neo4j can traverse these relationship paths in milliseconds because edges are stored as pointers. When you view someone’s profile, LinkedIn instantly shows “How you’re connected” (e.g., “You → John Smith → Jane Doe → This Person”), a query that would crush a traditional SQL database but is native to graph operations.
// Neo4j - LinkedIn Connection Recommendations
// Nodes
CREATE (u1:User {id: 'user_123', name: 'Alice Johnson', title: 'Software Engineer'})
CREATE (u2:User {id: 'user_456', name: 'Bob Smith', title: 'Product Manager'})
CREATE (u3:User {id: 'user_789', name: 'Carol Wang', title: 'Data Scientist'})
CREATE (u4:User {id: 'user_101', name: 'David Lee', title: 'Engineering Manager'})
CREATE (c1:Company {name: 'TechCorp'})
CREATE (c2:Company {name: 'StartupXYZ'})
CREATE (s1:School {name: 'MIT'})
// Relationships
CREATE (u1)-[:CONNECTED_TO {since: '2020-03-15'}]->(u2)
CREATE (u2)-[:CONNECTED_TO {since: '2019-07-22'}]->(u3)
CREATE (u3)-[:CONNECTED_TO {since: '2021-01-10'}]->(u4)
CREATE (u1)-[:WORKS_AT]->(c1)
CREATE (u4)-[:WORKS_AT]->(c1)
CREATE (u1)-[:STUDIED_AT]->(s1)
CREATE (u3)-[:STUDIED_AT]->(s1)
// Query: Find 2nd degree connections for Alice with shared context
MATCH (alice:User {id: 'user_123'})-[:CONNECTED_TO]-(friend)-[:CONNECTED_TO]-(suggestion)
WHERE NOT (alice)-[:CONNECTED_TO]-(suggestion) AND alice <> suggestion
WITH alice, suggestion, friend,
[(alice)-[:WORKS_AT]->(c)<-[:WORKS_AT]-(suggestion) | c.name] as sharedCompanies,
[(alice)-[:STUDIED_AT]->(s)<-[:STUDIED_AT]-(suggestion) | s.name] as sharedSchools
RETURN suggestion.name, suggestion.title,
collect(DISTINCT friend.name) as mutualConnections,
sharedCompanies, sharedSchools
ORDER BY size(mutualConnections) DESCExample Cases for the Database
- Social network platforms (friend connections, recommendations)
- Fraud detection systems analyzing transaction patterns
- Recommendation engines
- Network and IT infrastructure topology
- Knowledge graphs and semantic data
- Supply chain and logistics optimization
When not to Use the Database Avoid when your data is primarily tabular with few relationships, when you need simple CRUD operations on independent entities, or when the learning curve and specialized tooling are concerns for your team.
| Pros | Cons |
|---|---|
| Efficient for highly connected data | Steeper learning curve |
| Eliminates complex joins | Less mature ecosystem than RDBMS |
| Intuitive relationship modeling | Can be overkill for simple data |
| Fast traversal of relationships | Specialized query language (Cypher) |
Search Engines (Elasticsearch, Apache Lucene)
Brief Summary of Database/Technology Search engines like Elasticsearch (built on Apache Lucene) are similar to document-based databases but include sophisticated text processing and indexing capabilities. Under the hood, they analyze and tokenize text content, creating inverted indexes that enable fast full-text searches. They include ranking algorithms, fuzzy matching for typos, synonyms, and other features that dramatically improve search user experience. However, these capabilities come at the cost of higher computational and storage requirements.
Real-World Example GitHub Code Search: GitHub uses Elasticsearch to enable developers to search across billions of lines of code in millions of repositories. When you search for a function name like “getUserProfile” across GitHub, Elasticsearch must handle typos (“getUserProifle”), case variations (“getuserprofile”), and rank results by relevance—prioritizing exact matches in popular repositories over partial matches in obscure projects. Traditional databases would require exact string matching and couldn’t handle fuzzy searches efficiently. Elasticsearch tokenizes code during indexing, breaking “getUserProfile” into searchable terms and creating an inverted index that maps each term to document locations. It applies relevance scoring based on factors like term frequency, repository stars, and recency. Elasticsearch also powers GitHub’s filter system, allowing searches like “language:Python stars:>1000 created:>2023”, combining full-text search with structured filters. The cost: GitHub runs massive Elasticsearch clusters consuming significant resources, but the developer experience would be impossible with a standard database—imagine trying to find a specific function across all of GitHub using SQL LIKE queries.
// Elasticsearch - GitHub Code Search Index
// Index Mapping
{
"mappings": {
"properties": {
"repository": {"type": "keyword"},
"file_path": {"type": "keyword"},
"code_content": {
"type": "text",
"analyzer": "code_analyzer",
"fields": {
"exact": {"type": "keyword"}
}
},
"language": {"type": "keyword"},
"stars": {"type": "integer"},
"last_updated": {"type": "date"}
}
}
}
// Sample Document
{
"_index": "github-code",
"_id": "repo123_file456",
"_source": {
"repository": "facebook/react",
"file_path": "packages/react/src/ReactHooks.js",
"code_content": "export function useState(initialState) {\n const dispatcher = resolveDispatcher();\n return dispatcher.useState(initialState);\n}",
"language": "JavaScript",
"stars": 215000,
"last_updated": "2025-10-15T08:30:00Z"
}
}
// Search Query
GET /github-code/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"code_content": {
"query": "getUserProfile",
"fuzziness": "AUTO"
}
}
}
],
"filter": [
{"term": {"language": "Python"}},
{"range": {"stars": {"gte": 1000}}}
]
}
}
}Example Cases for the Database
- Full-text search for e-commerce products
- Log aggregation and analysis (ELK stack)
- Application search functionality
- Document management systems
- Real-time analytics dashboards
When not to Use the Database Avoid when simple exact-match queries suffice, when budget constraints are tight (expensive to run at scale), or when you don’t need advanced search features. Not ideal as a primary data store for transactional data.
| Pros | Cons |
|---|---|
| Powerful full-text search | Expensive to run at scale |
| Ranking and relevance scoring | Complex to configure and tune |
| Handles typos and fuzzy matching | High resource consumption |
| Real-time indexing capabilities | Not suitable as primary database |
| Rich query DSL | Eventual consistency issues |
Multimodel Databases (ArangoDB, FaunaDB)
Brief Summary of Database/Technology Multimodel databases support multiple data models (document, graph, key-value, etc.) within a single database system. They allow developers to work with different data paradigms without managing multiple database technologies. Many modern multimodel databases integrate with GraphQL, enabling developers to describe exactly how they want to retrieve data using a flexible query language that spans different data models.
Real-World Example E-Commerce Product Catalog with Recommendations: An online retailer could use ArangoDB to handle both product catalogs (document model) and recommendation engines (graph model) in one system. Each product is stored as a flexible document containing different attributes—a laptop has specs like RAM and processor, while a shirt has size and fabric. Simultaneously, the graph model tracks relationships: “customers who bought X also bought Y,” “this product is similar to that product,” and “users who viewed this item.” When a customer views a laptop, the system retrieves the product document (document query) and simultaneously traverses the graph to find related products and personalized recommendations (graph query)—all in a single database query using ArangoDB’s AQL language. Without a multimodel database, you’d need MongoDB for products and Neo4j for recommendations, requiring complex data synchronization and multiple queries. The trade-off: while ArangoDB handles both workloads adequately, a specialized graph database like Neo4j might perform relationship traversals faster, and MongoDB might handle larger document collections more efficiently. Multimodel databases excel when you need “good enough” performance across multiple paradigms without operational complexity.
// ArangoDB - E-Commerce Multimodel
// Document Collection: Products
{
"_key": "laptop_001",
"_id": "products/laptop_001",
"name": "MacBook Pro 16-inch",
"category": "Electronics",
"price": 2499.99,
"specs": {
"ram": "32GB",
"processor": "M3 Pro",
"storage": "1TB SSD",
"screen": "16-inch Retina"
},
"inStock": true
}
{
"_key": "shirt_042",
"_id": "products/shirt_042",
"name": "Cotton T-Shirt",
"category": "Clothing",
"price": 24.99,
"attributes": {
"size": "M",
"color": "Navy Blue",
"fabric": "100% Cotton"
},
"inStock": true
}
// Graph Collection: Relationships
// Edge: purchased_together
{
"_from": "products/laptop_001",
"_to": "products/mouse_015",
"weight": 145,
"type": "purchased_together"
}
// Edge: viewed_together
{
"_from": "products/laptop_001",
"_to": "products/laptop_002",
"weight": 89,
"type": "similar_product"
}
// AQL Query: Get product with recommendations
FOR product IN products
FILTER product._key == 'laptop_001'
LET recommendations = (
FOR v, e IN 1..1 OUTBOUND product purchased_together
SORT e.weight DESC
LIMIT 5
RETURN {product: v.name, score: e.weight}
)
RETURN {
product: product,
recommendations: recommendations
}
Example Cases for the Database
- Applications requiring multiple data paradigms (documents + graphs)
- Microservices architectures needing flexible data access
- Projects wanting to reduce database infrastructure complexity
- Applications with evolving data requirements
When not to Use the Database Avoid when a single specialized database would suffice and perform better, when you need the absolute best performance for a specific paradigm, or when your team lacks experience with multiple data models.
| Pros | Cons |
|---|---|
| Flexibility across data models | Jack of all trades, master of none |
| Reduced infrastructure complexity | Potentially lower performance per model |
| Single query language across models | Steeper learning curve |
| Good for evolving requirements | Less specialized optimization |
Linked Map of Contexts